一、语法
1.1 普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 字符 | 描述 | 实例 |
|---|---|---|
| [ABC] | 匹配 […] 中的所有字符,例如 [ABC] 匹配字符串 “123abc456edf789ABC” 中所有的 ABC 字母。 | 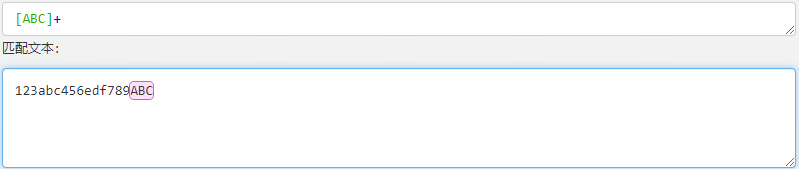 |
| [^ABC] | 匹配除了 […] 中字符的所有字符,例如 [^ABC] 匹配字符串 “123abc456edf789ABC” 中除了 ABC 字母的所有字母 | 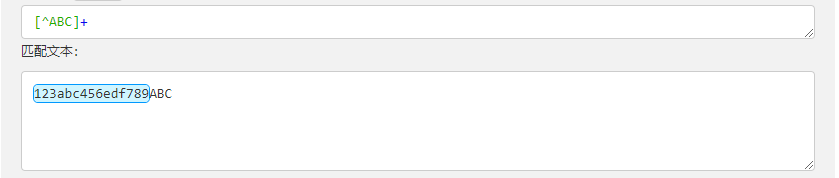 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母. | 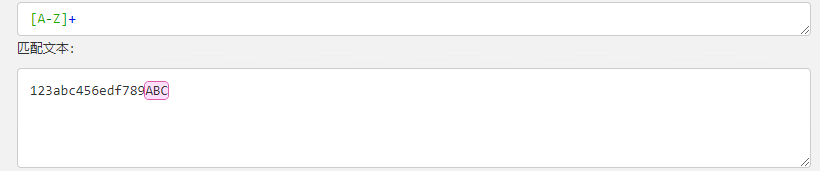 |
| [a-z] | [a-z] 表示所有小写字母。 | 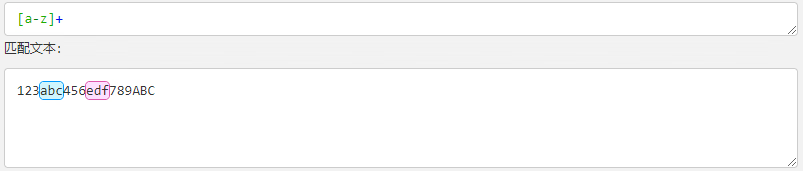 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [ ^\n\r]。 | 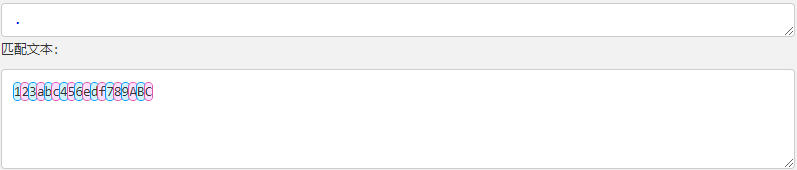 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 | ![\s\S] |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] | 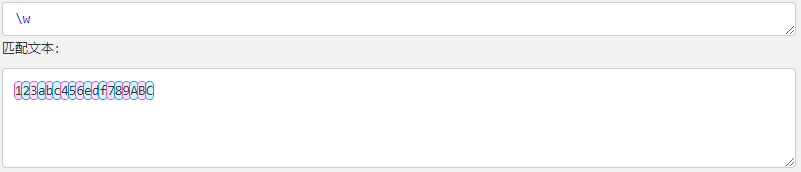 |
1.2 非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
1.3 特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 ,简单的说就是表示任何字符串的意思。如果要查找字符串中的 符号,则需要对 进行转义,即在其前加一个 *,runo*ob** 匹配字符串 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符”转义”,即,将反斜杠字符** 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\’ 匹配 “\”,而 ‘(‘ 则匹配 “(“。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
二、限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 “do” 、 “does”、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 “Bob” 中的 o,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 “Bob” 中的 o,但能匹配 “foooood” 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 “fooooood” 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
以下正则表达式匹配一个正整数,[1-9]设置第一个数字不是 0,[0-9]* 表示任意多个数字:
[1-9][0-9]*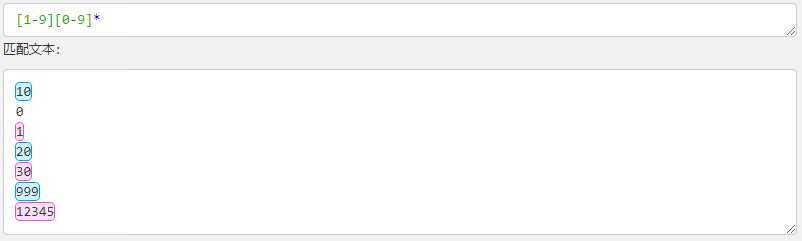
匹配一个1-99的整数:第一位数字是1-9范围内的数字,第二位数字是0-9范围内的数字。且第二位数字最少出现0次,最多出现1次。
[1-9][0-9]?
[1-9][0-9]{1,2}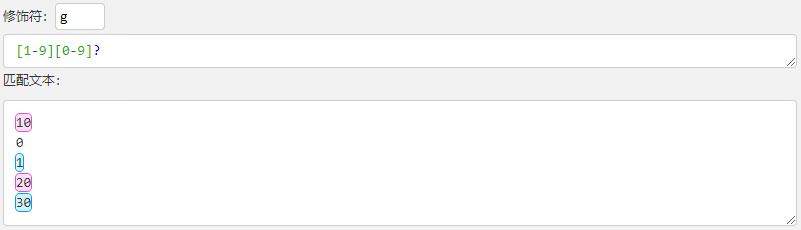
三、学习笔记
3.0 介绍
Regex 是正则表达式(Regular Expression)的简称。它便于匹配、查找和管理文本。
什么是「正则表达式」?
正则表达式是表示搜索模式的字符串,常缩写成 Regex 或 Regexp。它常用于查找和替换文本中的字词。此外,我们可以测试文本是否符合我们设置的规则。
例如,我们想查找文件名列表中,扩展名是 pdf 的文件,那我们只需输入 ^\w+\.pdf$ 就可以找到。
3.1 基本匹配
3.1.1 基本匹配
我们想要查找的字符或单词可以直接输入,就像搜索一样。例如,要找出文本中的 curious 一词,只需输入同样的内容。
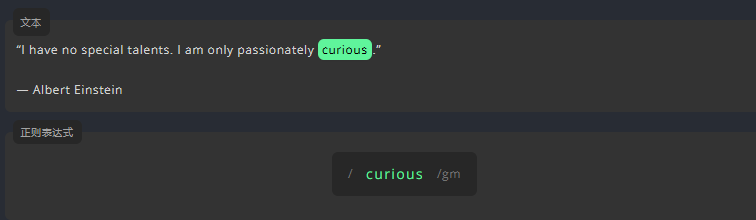
练习:匹配文本中的单词 of
“Every man takes the limits of his own field of vision for the limits of the world.”
― Arthur Schopenhauer参考答案:
/of/g3.1.2 点. :匹配任何字符
. 允许匹配任何字符,包括特殊字符和空格。
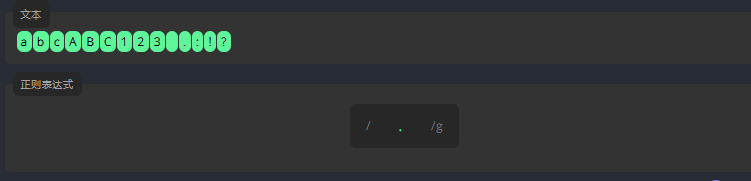
3.1.3 字符集 [abc]
如果一个词中的字符可以是各种字符,我们就将所有的可选字符写进中括号 [] 中。例如,为了查找文本中的所有单词,我们需要编写表达式,在 [] 中相邻地输入字符 a、e、i、o、u。
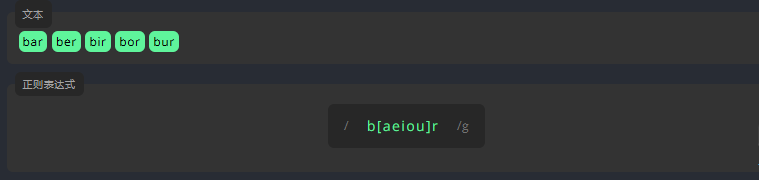
练习: 匹配文本中所有单词
beer deer feer参考答案:
/[bdf]eer/g3.1.4 否定字符集 [^abc]
为了查找下方文本的所有单词(ber 和 bor 除外),我们可以在 [] 中的 ^ 后面并排输入 e 和 o。
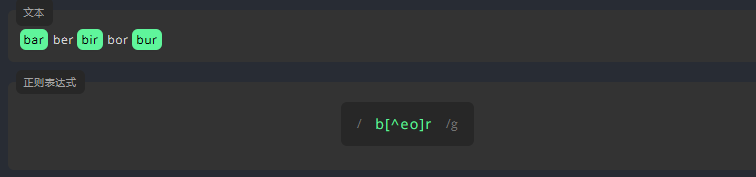
练习:匹配除 beor 和 beur 以外的所有单词。
bear beor beer beur参考答案:
/be[^ou]r/g3.1.5 字母范围 [a-z]
为了查找指定范围的字母,我们需要将起始字母和结束字母写进 [] 中,中间用连字符 - 分隔。它区分大小写。
请编写表达式,匹配 e 和 o 之间所有的小写字母,包括它们本身。
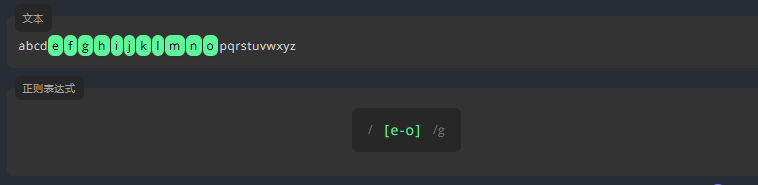
练习:匹配 g 到 k之间的所有字母包括他们本身
abcdefghijklmnopqrstuvwxyz参考答案:
/[g-k]/g3.1.6 数字范围 [0-9]
为了查找指定范围的数字,我们需要在 [] 中输入起始和结束数字,中间用连字符 - 分隔。
请编写表达式,匹配 3 到 6 之间的所有数字,包括它们本身。
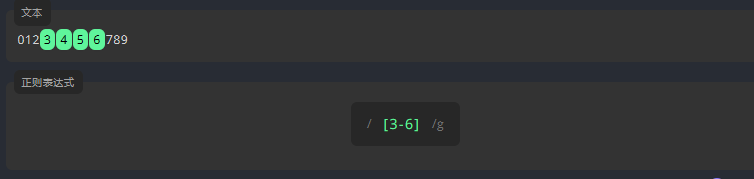
练习:匹配 2–7之间的所有数字,包括他们本身
参考答案:
/[2-7]/g3.2 重复
一些特殊字符用来指定一个字符在文本中重复的次数。它们分别是加号 +、星号 * 和问号 ?。
3.2.1 星号:*
我们在字符后面加上 *,表示一个字符完全不匹配或可以匹配多次。
例如,表示字母 e 在下方文本中不出现,只出现 1 次或者并排出现多次。
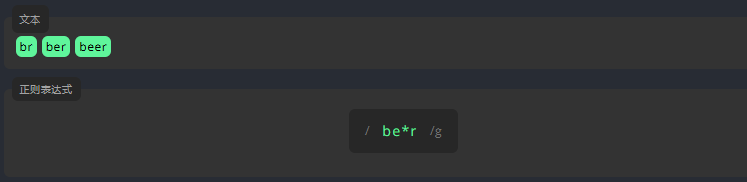
练习:
编写表达式,用 *匹配下方文本中,没有或存在多个字母 e的单词。
dp dep deep参考答案:
/de*p/g3.2.2 加号:+
为了表示一个字符可以出现一次或多次,我们将 + 放在它后面。
例如,表示 e 在下方文本中出现一次或多次。
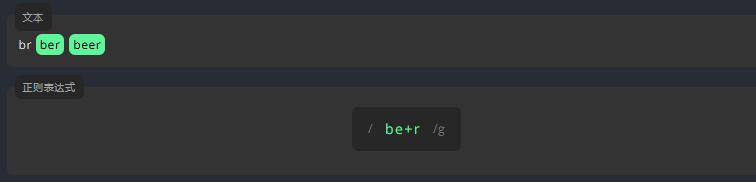
练习:
编写表达式,用 *匹配下方文本中,字母 e出现一次或多次的单词。
dp dep deep参考答案:
/de+p/g3.2.3 问号:?
为了表示一个字符是可选的,我们在它后面加一个 ?
例如,表示下方文本中的字母 u 是可选的。
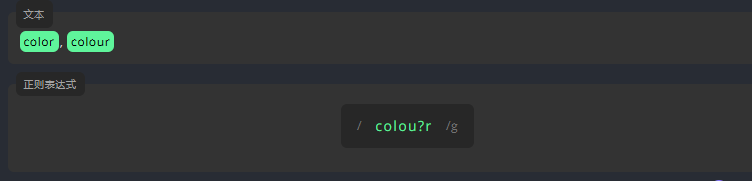
练习:
编写表达式,用 ?表示字母 n 在文本中是可选的,使 a 和 an 都可以匹配到。
a an参考答案:
/an?/g3.2.4 大括号-1:{n}
为了表示一个字符出现的确切次数,我们在该字符的末尾,将它出现的次数写进大括号 {} 中,如 {n}。
例如,表示下方文本中的字母 e 只能出现 2 次。
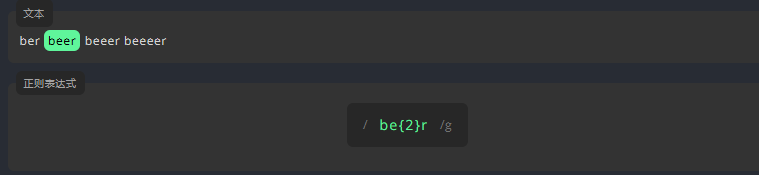
练习: 用 {} 编写表达式,匹配文本中,位数为 4 的阿拉伯数字。
Release 10/9/2021参考答案:
/[0-9]{4}/g
/\d{4}/g3.2.5 大括号-2:{n,}
为了表示一个字符至少出现多少次,我们在该字符的末尾,将它至少应出现的次数写进大括号 {} 中,并在数字后面加上逗号 ,,如 {n, }。
例如,表示下方文本中的字母 e 至少出现 3 次。
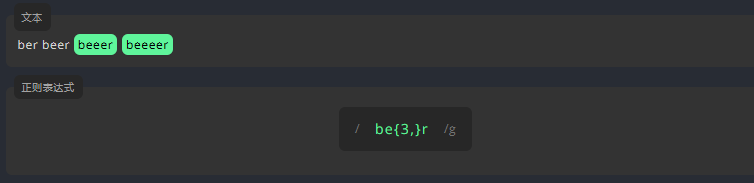
练习: 用 {} 编写表达式,匹配文本中,位数至少为 2 的阿拉伯数字。
Release 10/9/2021参考答案:
/[0-9]{2,}/g
/\d{2,}/g3.2.6 大括号-3:{x,y}
为了表示一些字符出现的次数在某个数字范围内,我们在该字符的末尾,将它至少和至多出现的次数写进大括号 {} 中,中间用逗号 , 分隔,如 {x,y}。
例如,匹配下方文本中,字母 e 出现 1 至 3 次的单词。
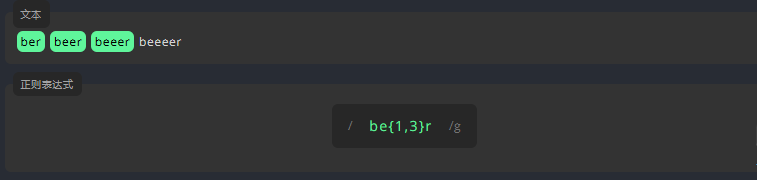
练习: 用 {} 编写表达式,匹配文本中,位数为 1 至 4 的阿拉伯数字。
Release 10/9/2021参考答案:
/[0-9]{1,4}/g
/\d{1,4}/g3.3 分组
3.3.1 括号 ():
我们可以对一个表达式进行分组,并用这些分组来引用或执行一些规则。为了给表达式分组,我们需要将文本包裹在 () 中。
现在,请尝试为下方文本中的 haa 构造分组。
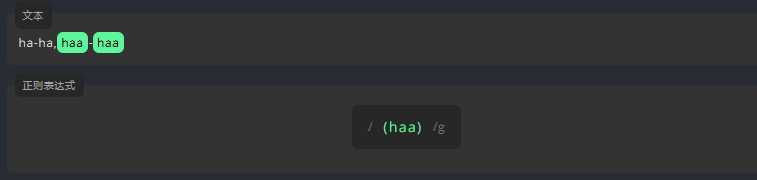
3.3.2 引用组
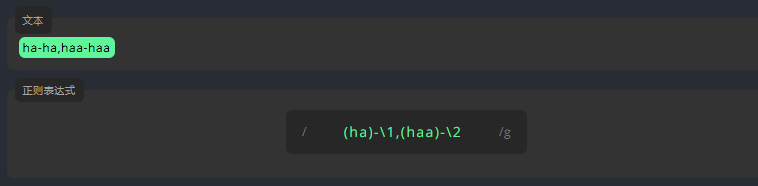
单词 ha 和 haa 分组如下。第一组用 \1 来避免重复书写。这里的 1 表示分组的顺序。
请在表达式的末尾键入 \2 以引用第二组。
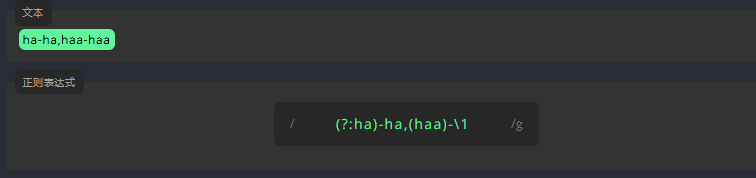
3.3.3 括号 (?:):非捕获分组
我们可以对表达式进行分组,并确保它不被引用捕获。
例如,下面有两个分组,但我们用 \1 引用的第一个组实际上是指向第二个组,因为第一个是未被捕获的分组。
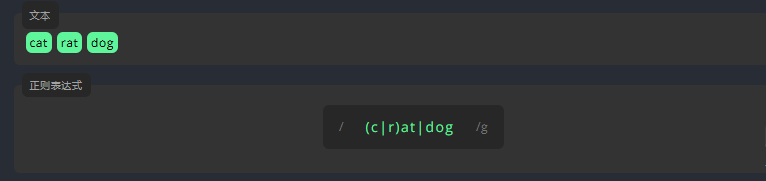
3.3.4 竖线 |
竖线允许一个表达式包含多个不同的分支。所有分支用 | 分隔。和在字符层面上运作的字符集 [abc] 不同,分支在表达式层面上运作。
例如,下面的表达式同时匹配 cat 和 rat。请在末尾添加另一个 |,并输入 dog 以匹配所有单词。
3.4 特殊字符
3.4.1 转义字符
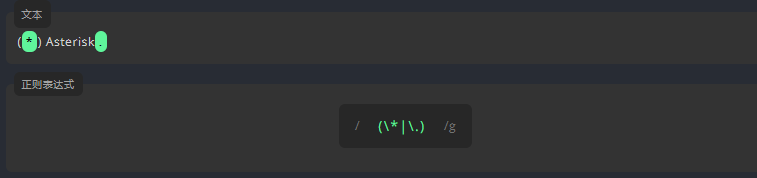
在书写正则表达式时,我们会用到 { } [ ] / \ + * . $^ | ? 这些特殊字符 。为了匹配这些特殊字符本身,我们需要通过 \ 将它们转义。例如,要匹配文本中的 . 和 *,我们需要在它们前面添加一个 \。
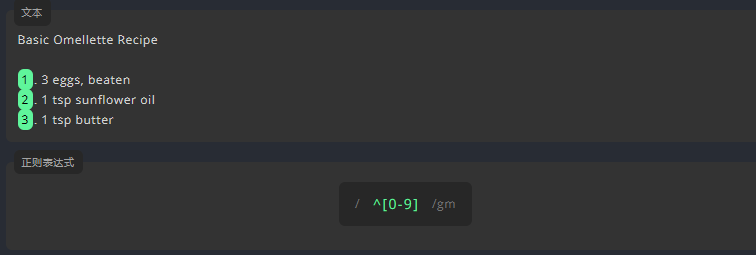
3.4.2 插入符 ^:匹配字符串的开始
我们用 [0-9] 查找数字,若仅查找行首的数字,请在表达式前面加上 ^。
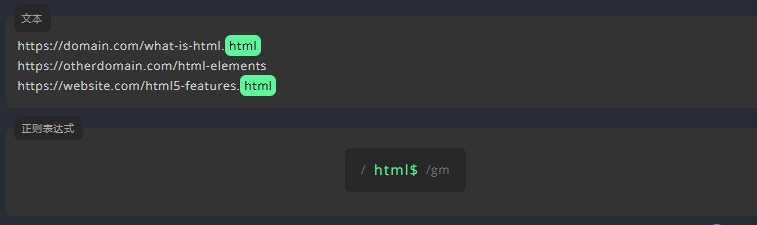
3.4.3 美元符号 $:匹配字符串的结束
让我们在 html 的后面添加 $,来查找仅在行末出现的 html。
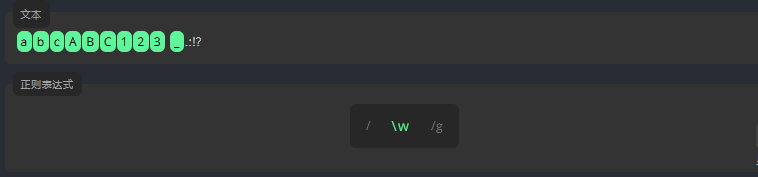
3.4.4 单词字符 \w: 字母、数字和下划线
表达式 \w 用于查找字母、数字和下划线。让我们用表达式 \w 来查找文本中的单词字符。
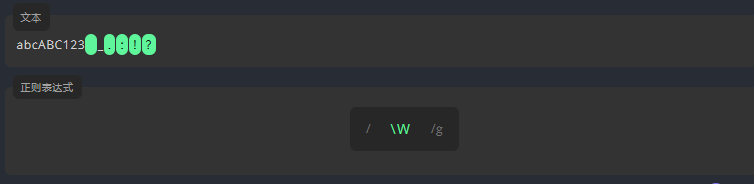
3.4.5 非单词字符 \W
\W 匹配除字母、数字和下划线之外的字符。
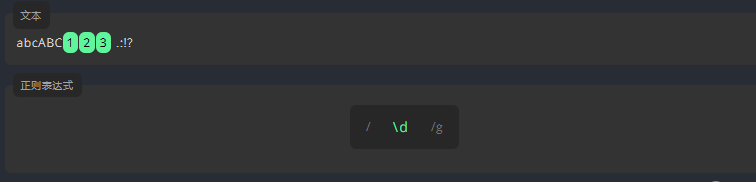
3.4.6数字字符 \d
\d 仅用来匹配数字。
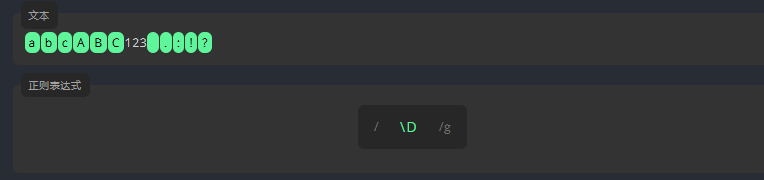
3.4.7 非数字字符 \D
\D 匹配除数字之外的字符。
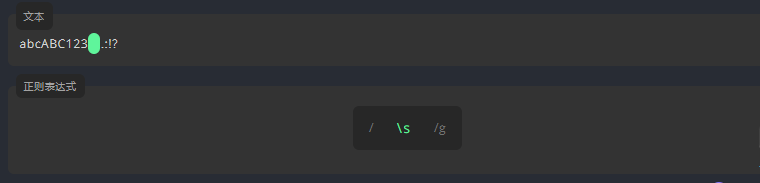
3.4.8 空白符 \s
\s 仅匹配空白字符。
3.4.9非空白符 \S
\S 匹配除空白符之外的字符。
3.5 零宽断言
如果我们希望正在写的词语出现在另一个词语之前或之后,我们需要使用「零宽断言」。
3.5.1 正向先行断言: (?=)
例如,我们要匹配文本中的小时值。为了只匹配后面有 PM 的数值,我们需要在表达式后面使用正向先行断言 (?=),并在括号内的 = 后面添加 PM。
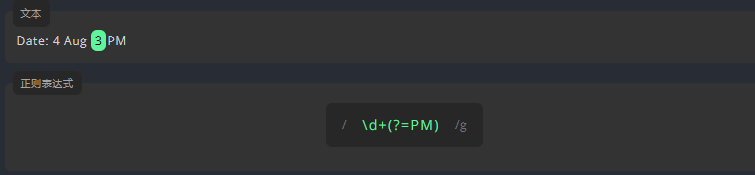
3.5.2 负向先行断言: (?!)
例如,我们要在文本中匹配除小时值以外的数字。我们需要在表达式后面使用负向先行断言 (?!),并在括号内的 ! 后面添加 PM,从而只匹配没有 PM 的数值。

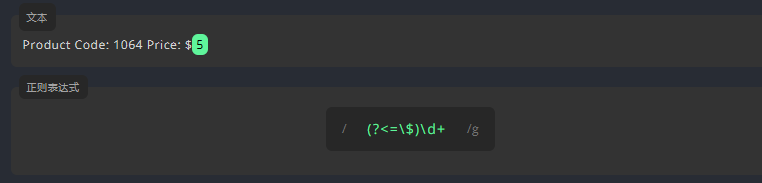
3.5.3 正向后行断言: (?<=)
例如,我们要匹配文本中的金额数。为了只匹配前面带有 $ 的数字。我们要在表达式前面使用正向后行断言 (?<=),并在括号内的 = 后面添加 \$。
3.5.4 负向后行断言: (?<!)
例如,我们要在文本中匹配除价格外的数字。为了只匹配前面没有 $ 的数字,我们要在表达式前用负向后行断言 (?<!),并在括号内的 ! 后面添加 \$。
3.6 标志
标志改变表达式的输出。这就是标志也称为 修饰符 的原因。标志决定表达式是否将文本视作单独的行处理,是否区分大小写,或者是否查找所有匹配项。
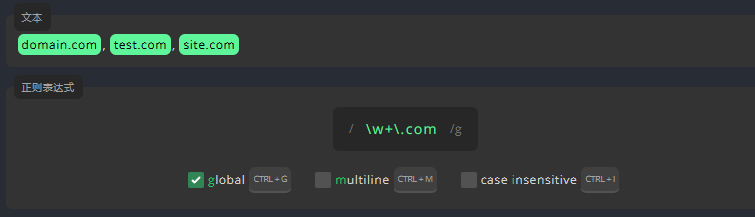
3.6.1 全局标志 global
全局标志使表达式选中所有匹配项,如果不启用全局标志,那么表达式只会匹配第一个匹配项。现在,请启用全局标志,以便匹配所有匹配项。
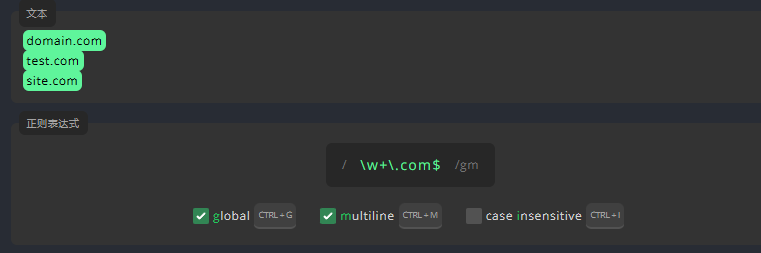
3.6.2 多行标志 multiline
正则表达式将所有文本视作一行。但如果我们使用了多行标志,它就会单独处理每一行。这次,我们将根据每一行行末的规律来写出表达式,现在,请启用多行标志来查找所有匹配项。
3.6.3 忽略大小写标志 case insensitive
为了使我们编写的表达式不再大小写敏感,我们必须启用 不区分大小写 标志。

3.7 贪婪匹配
正则表达式默认执行贪婪匹配。这意味着匹配内容会尽可能长。请看下面的示例,它匹配任何以 r 结尾的字符串,以及前面带有该字符串的文本,但它不会在第一个 r 处停止匹配。
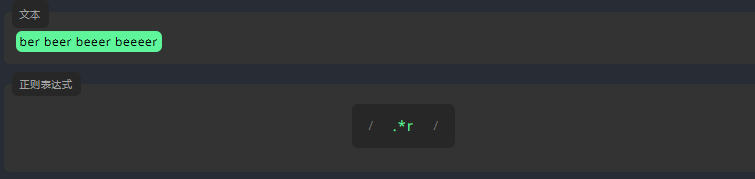
3.8 懒惰匹配
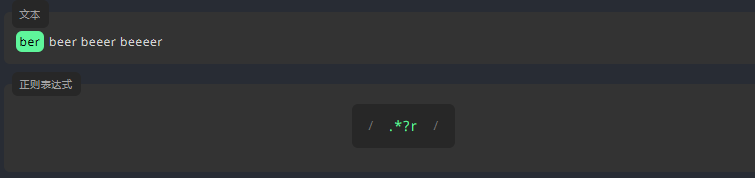
与贪婪匹配不同,懒惰匹配在第一次匹配时停止。下面的例子中,在 * 之后添加 ?,将查找以 r 结尾且前面带有任意字符的第一个匹配项。这意味着本次匹配将会在第一个字母 r 处停止。

![[\s\S]](https://m.360buyimg.com/babel/jfs/t1/20999/31/18496/6308/62e4f3adE3151e6f4/475feef437f4bcb8.png){kind=link}